

091
[R] 단일&다중변수자료의 탐색 본문
1. 자료
- 자료의 특성과 변수의 개수에 따른 분류를 통해 범주/연속형 자료로, 단일/다중변수 자료로 나눌 수 있습니다.
-> 자료의 특성에 따른 분류
• 범주형 자료: 숫자의 크고 작음이 아니라, 종류나 그룹으로 구분하기 위해 수집된 데이터로, 성별, 혈액형, 선호하는 색 등이 있습니다. R에는 factor라는 타입으로 다룰 가능성이 높습니다.
• 연속형 자료: 측정이나 계량을 통해 얻어진 숫자 형태의 데이터로, 값들끼리 대소 비교나 평균, 최소, 최대 등의 산술 연산이 가능합니다.
-> 변수의 개수에 따른 분류
• 단일변수 자료: 딱 한가지의 변수만 측정하여 모은 데이터로, 열이 하나인 상태라고 보면 됩니다. 일변량 자료라고도 합니다.
• 다중변수 자료: 두 개 이상의 변수를 동시에 측정하여 모은 데이터이며, 변수가 두개인 경우에는 이변량 자료라고 합니다.
2. 자료 분류와 관련된 탐색방법
(1) 범주형 자료 + 단일변수 자료

- 도수분포표란 데이터의 구간이나, 항목의 범주가 몇 개씩 있는지 개수를 세어 요약한 표입니다. table()은 범주형 자료에서 해당 자료가 몇 개가 있는지 알려주는 함수입니다.
favorite <- c("WINTER","SUMMER","SPRING","SUMMER","SUMMER",
"FALL","FALL","SUMMER","SPRING","SPRING")
favorite
table(favorite)
# favorite
# FALL SPRING SUMMER WINTER
# 2 3 4 1
table(favorite)/length(favorite) #비율출력
# favorite
# FALL SPRING SUMMER WINTER
# 0.2 0.3 0.4 0.1- 막대그래프나 원 그래프의 경우, 두 그래프 함수 모두 입력받은 숫자의 크기만큼 막대의 높이, 조각의 각도를 나누기 때문에 barplot, pie 함수를 사용할 때는 내부에 table(범주형 자료) 값을 넣어줘야합니다.
ds <- table(favorite)
ds
barplot(ds,main="favoirte season")
ds <- table(favorite)
ds
pie(ds,main="favoirte season")-> main=""은 그래프의 제목을 지어주는 속성값입니다.


drink <- c("커피","주스","물","커피","탄산","주스",
"물","커피","탄산","주스","커피","물","탄산","커피","주스")
freq_table <- table(drink)
freq_table
barplot(freq_table,
main="음료 판매 현황",
xlab="음료 종류",
ylab="판매 수량",
col="skyblue")
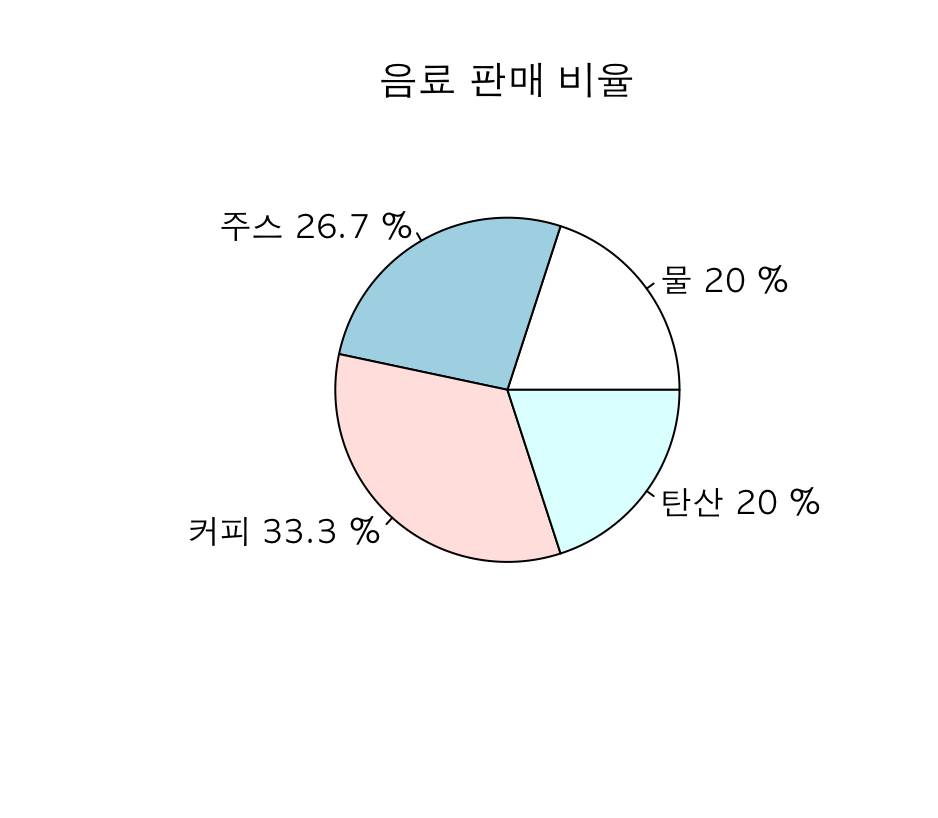
pie(freq_table, labels=paste(names(freq_table),
round(freq_table/sum(freq_table)*100,1),"%"), main="음료 판매 비율")-> 아래의 두 번째 이미지의 그래프를 보면 labels를 직접 지정한걸 알 수 있습니다. labels 라는 속성 값을 이용해주었습니다. 복잡해보이는 속성값은 사실 paste로 names() + 비율 + %를 띄어쓰기를 넣어서 하나의 글자로 이어주며, table의 names로 이름(주스, 커피 등)과 그 다음에는 round(소수, 1)로 소수점 한자리 수까지만 남기며 내부 freq_table/sum(freq_table)*100은 비율이 나오게합니다. 그 다음에 최종적으로 %붙여 비율을 나타내게 해준 것입니다.

favorite.color <- c(2,3,2,1,1,2,2,1,3,2,1,3,2,1,2)
ds <- table(favorite.color)
ds
# favorite.color
# 1 2 3
# 5 7 3
colors <- c("green","red","blue")
names(ds) <- colors
ds
# green red blue
# 5 7 3
barplot(ds,main="favorite color") #col=colors 생략가능
pie(ds,main="favorite color")-> 범주형 자료를 숫자로 받은 다음, names로 따로 이름을 지정할 수도 있습니다.
Q. favorite.color라는 내용은 ds 출력할 때 왜 사라진건가요?
A. table() 함수가 만들어낸 결과물은 얼핏 보면 1차원 데이터같지만, R 내부적으로 1차원 배열이라는 특별한 차원 데이터로 취급하며, 큰 차원 제목을 가지고 있습니다. 이때 names라는 1차원 전용함수로 작성을 해버렸기 때문에 이 데이터가 1차원 백터처럼 취급해도 된다는 의미로 받아들여져 내부적으로 가지고 있던 차원 제목이 사라지게 됩니다. dimnames()를 사용하면 큰 차원 제목을 둘 수 있습니다.
dimnames(ds) <- list(favorite.color= colors)
ds
#favorite.color
#green red blue
# 5 7 3
(2) 연속형 자료 + 단일변수 자료

- 평균은 모든 데이터의 합을 데이터의 개수로 나눈 값으로, 극단값에 영향을 많이 받는, 민감한 편입니다. 중앙값은 말 그대로 중앙에 위치한 값으로, 데이터의 개수가 홀수일 때는 중앙값이, 짝수일 때는 중간의 두 수의 평균을 의미합니다. 그러기 때문에 큰 극단값이 있어도 영향을 거의 받지 않습니다.
weight <- c(60,62,64,65,68,69)
weight.heavy <- c(weight,120)
weight #[1] 60 62 64 65 68 69
weight.heavy #[1] 60 62 64 65 68 69 120
mean(weight) #[1] 64.66667
mean(weight.heavy) #[1] 72.57143
median(weight) #[1] 64.5
median(weight.heavy) #[1] 65- 사분위수(quantile)란 주어진 자료에 있는 값들을 크기순으로 나열했을 때 이것을 4등분하는 지점에 있는 값들을 의미합니다. R 내부에 있는 quantile이라는 함수를 사용하여 기본적으로 4분위값을 출력할 수 있으며, (0:10)/10등의 표현을 사용해 원하는 퍼센트(%) 위치에 어떤 값이 있는지 찾아주는 함수입니다.
mydata <- c(60,62,64,65,68,69,120)
quantile(mydata)
#quantile(mydata, (0:4)/4), 결과값이 아래와 같음
# 0% 25% 50% 75% 100%
# 60.0 63.0 65.0 68.5 120.0
quantile(mydata,(0:10)/10)
# 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
# 60.0 61.2 62.4 63.6 64.4 65.0 66.8 68.2 68.8 89.4 120.0
- 히스토그램(histogram)은 외관상 막대그래프와 비슷한 그래프로, 연속형 자료의 분포를 시각화할 때 사용합니다. 막대그래프를 그리려면 값의 종류별 개수를 셀 수 있어야하지만, 키나 몸무게 같은 연속형 자료는 값의 종류라는 개념이 없기 때문에 히스토그램을 사용하여 연속형 자료에서는 구간을 나누고 구간에 속하는 값들의 개수를 세는 방식을 사용합니다.
head(cars) #내장 데이터셋
# speed dist
# 1 4 2
# 2 4 10
# 3 7 4
# 4 7 22
# 5 8 16
# 6 9 10
dist <- cars[,2]
hist(dist,
main="Histogram for 제동거리",
xlab="제동거리",
ylab="빈도수",
border="blue", #막대 테두리색
col="green", #막대 색
las=2) #x,y축 글씨 방향을 조절
#las=0, y(눕기), x(서기)
#las=1, y(서기), x(서기)
#las=2, y(서기), x(눕기)
#las=3, y(눕기), x(눕기)-> cars은 50개의 관측치와 2개의 변수(열)로 이루어진 내장 데이터셋으로, 속도가 빨라질 수록 제동거리가 길어지는 가에 대한 값을 확인할 수 있습니다.




dist <- cars[,2]
quantile(dist)
# 0% 25% 50% 75% 100%
# 2 26 36 56 120
boxplot(dist, main="자동차 제동거리",
ylim=c(-10, 130))-> boxplot의 아래 수염은 마지노선(1.5*IQR)을 넘지 않는 선에서 실제 데이터가 존재하는 끝과 끝을 나타내는 것입니다.

(3) 연속형 자료 + 다중변수 자료

- plot은 산점도, 선그래프, 계단형 그래프등 데이터 종류에 따라 다양한 그래프를 그릴 수 있는 함수입니다.
wt <- mtcars$wt
mpg <- mtcars$mpg
plot(wt,mpg,
main="중량-연비 그래프",
xlab="중량",
ylab="연비(MPG)",
col="red",
pch=19)
#par(family = "AppleGothic") #mac 그래프 한글-> 이 경우에는 기본 type값인 "p"(point)가 사용된 두 변수의 산점도를 나타낸 경우입니다. pch를 통해 점의 모양을 나타낼 수 있습니다.(0부터 25번의 가짓수가 있습니다.) col을 통해 점이나 선의 색상을 나타낼 수 있으며, main(제목), xlab(x축이름), ylab(y축이름)을 지정할 수 있습니다. mac의 경우 한글을 사용하기 위해서 마지막 par(...)를 실행해줘야합니다.
-> mtcars는 cars보다 더 복잡한 다중변수 분석을 연습할 때 많이 사용되는 데이터셋으로, 자동차 32종의 성능 데이터입니다. 32개의 관측치와 11개의 변수(열)로 이루어져있습니다.


+) 점 모양과 관련된 함수는 아래 티스토리를 참고하였습니다. 21~25까지의 점 모양은 테두리가 있는 도형으로, 위와 모형만 같지 설정에서 차이를 보입니다.
[R 강의] 67. 산점도 '점'의 모양 25가지
도구 R로 푸는 통계 67. 산점도 '점'의 모양 25가지 산점도를 꾸미는 방법을 이전에 다뤘었는데, 이번 강의에서는 점의 모양을 바꾸는 방법을 더 자세히 다루려고 합니다. 먼저 오늘 강의에 활용할
statools.tistory.com
month <- c(1:12)
late1 <- c(5,8,7,9,4,6,12,13,8,6,6,4)
late2 <- c(4,6,5,8,7,8,10,11,6,5,7,3)
plot(month, late1,
main="Late Students",
type="b",
lty=1, #선두께 지정시에는 lwd=2
col="red",
xlab="Month",
ylab="Late cnt")
lines(month,late2,
type="o",
col="blue")-> plot을 선그래프나 계단형 그래프 등으로 사용할 때는 type을 따로 지정해주면 됩니다. lty는 선의 종류를 lwd는 선의 두께를 나타냅니다.(type에 대한 설명을 하는 부분에서는 lwd의 기본값인 1이며, 아래 lty를 설명하는 부분에서 lwd가 2입니다.)



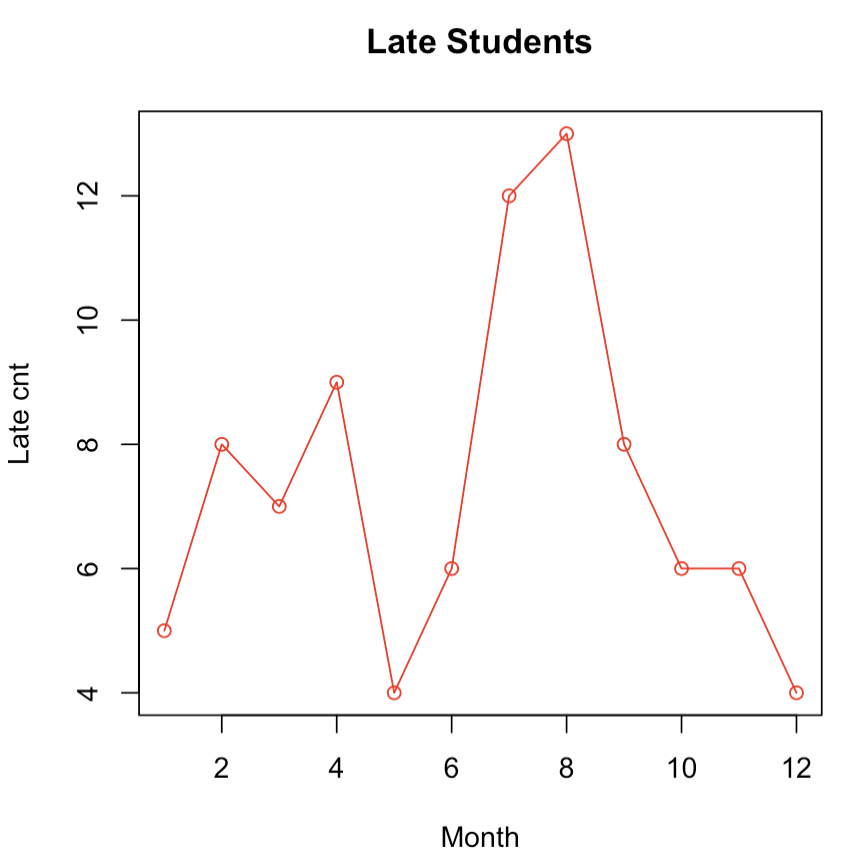
-> type="b"와 type="o"의 가장 큰 차이는 "b"는 점을 통과하지 않지만, "o"의 경우 점을 통과합니다.






-> lty가 1일 때는 실선, 2일때는 대시선(짧은 선들이 끊어져있는 형태), 3일때는 점선, 4일때는 점-대시선, 5일 때는 긴 대시선(2번보다 선의 길이가 길고 여백이 넓은 선들이 끊어져있는 형태), 6일때는 두가지 대시선입니다.
-> lines(...)는 새로운 그래프 창을 열거나 축을 만드는 함수가 아닌 기존의 plot()이 만들어둔 틀 안에서 파란색으로 late2 데이터를 type="o"로 덧그릴 때 사용하는 함수입니다.


plot(pressure$temperature,pressure$pressure)-> pressure은 수은의 온도가 올라갈 때 증기압이 어떻게 변하는지 기록한 과학/통계 데이터입니다.

- pairs는 산점도 행렬을 그려주는 함수로, 내부 타겟 안에 있는 4개(아래예시 변수개수)의 변수들이 짝지을 수 있는 모든 경우의 수의 산점도를 바둑판 모양으로 한번에 다 그려줍니다.
vars <- c("mpg","disp","drat","wt")
target <- mtcars[,vars] #행이름 지정
head(target)
pairs(target, main="Mulit Plots")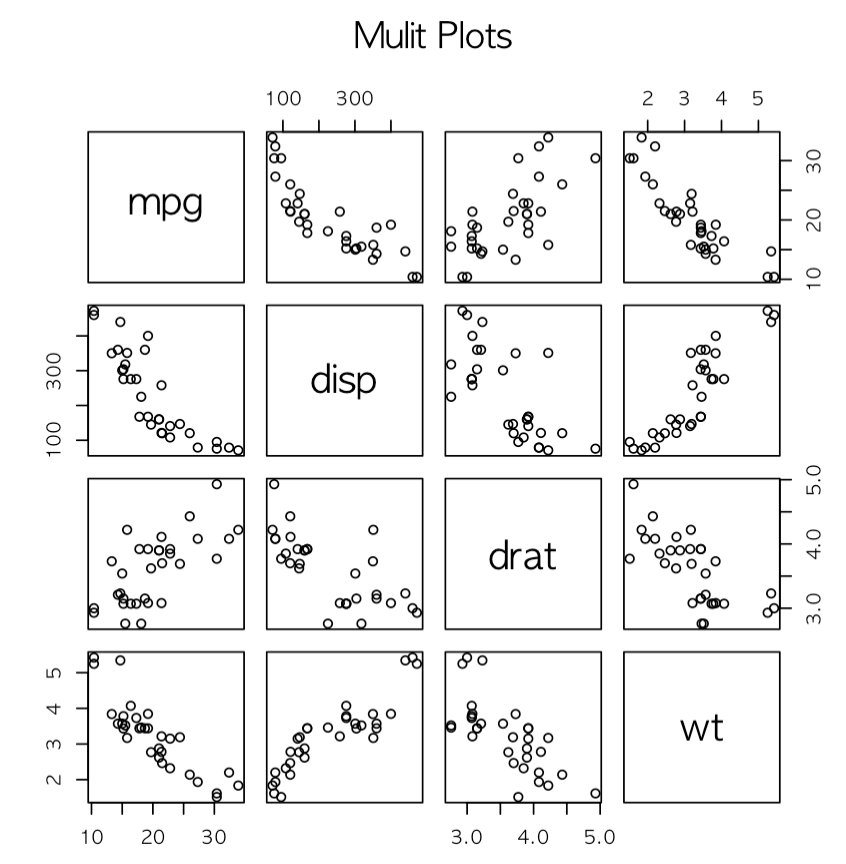
-> mpg(연비), disp(배기량), drat(리어 액슬 기어 비), wt(증량)에 대한 산점도 행렬로, 각각 x축, y축을 반대로 대칭을 이룹니다.
'Programming Language > R' 카테고리의 다른 글
| [R] 데이터 시각화(treemap, ggplot2) (0) | 2026.04.26 |
|---|---|
| [R] 데이터 전처리 (0) | 2026.04.26 |
| [R] 기초문법(조건문, 반복문, 함수) (0) | 2026.04.06 |
| [R] 파일 데이터 읽기/쓰기 (0) | 2026.04.06 |
| [R] 자료구조(3): 매트릭스(Matrix) & 데이터프레임(Dataframe) (0) | 2026.04.01 |



