

091
[R] 데이터 시각화(treemap, ggplot2) 본문
1. 데이터 시각화
- 데이터 시각화란 숫자 형태의 데이터를 그래프나 그림 등의 형태로 표현하는 과정을 의미합니다. 이 글에서는 treemap과 R 내장함수 중 버블차트를 만드는 함수와 그리고 ggplot을 이용해 이전에 설명했던 것보다 더 미적인 그래프를 그리는 것에 대해 설명합니다.
par(family = "AppleGothic") #mac 그래프 한글
install.packages("treemap")
install.packages("ggplot2")
library(treemap)
library(ggplot2)-> 외부 라이브러리를 사용하기 위해 install.packages() 함수를 사용해 다운 받고 library() 함수를 통해 import 해줍니다.
(1) treemap은 전체 데이터를 사각형으로 보고 각 항목이 차지하는 비율에 따라 사각형을 쪼개 보여주는 그래프입니다.
treemap(데이터, index=그룹, vSize= 크기, vColor=색깔, title=제목, type=모드)-> treemap() 함수에서 많이 사용되는 속성들이며, type의 경우 수치형 모드(value), 범주형 모드(index), 비교 모드(comp) 등 모드에 따라 다르게 지정해야하며, 기본형은 index값입니다.
f.data <- data.frame(
fCategory = c("Fruits","Fruits","Vegetables","Vegetables"),
fSubCategory = c("Apple","Banana","Carrot","Tomato"),
fValue = c(50,30,40,20)
)
f.data
treemap(f.data,
index=c("fCategory","fSubCategory"),
vSize="fValue",
title="과일 트리",
fontfamily.labels="AppleGothic",
fontfamily.title="AppleGothic")
#아래 fontfamily은 OS에 다른 글씨체를 지정해줘야할 수도 있습니다.-> 아래의 첫 번째 이미지의 그래프를 그릴 때 사용한 함수로, vColor 지정없이 index(대분류 그룹)에 지정한 값에 따라 알록달록한 값이 색칠됩니다. 각 사각형의 넓이는 vSize로 지정해줬던 50,30,40,20 등의 값입니다.



st <- data.frame(state.x77)
st <- data.frame(st, stname=rownames(st))
st
treemap(st,
index="stname",
vSize="Area",
vColor="Income",
type="value", #기본값은 type="index"인데 그렇게 쓰면 색이 알록달록함
title="USA states area and income")-> 기본으로 제공되는 미국 주의 관련된 matrix 데이터셋인 state.x77에다가 rownames와 같은 stname을 추가하여 data.frame을 만들어줍니다.(treemap은 기본적으로 데이터프레임 형태의 데이터만 받아들입니다.) 두 번째 이미지의 그래프는 대분류에 따라 색이 분리되어있었다면 세 번쨰 이미지처럼 알록달록했어야겠지만(주의 이름이 전부 다르니), vColor를 통해 수입을 기준으로 정해두고 type="value"로 지정하여 수치형 모드를 통해 숫자의 크기에 따라 색의 진하기를 지정하는 모드로 변경합니다.
(2) 버블차트는 산점도에 원의 크기라는 데이터를 하나 더 추가하여 총 3개의 변수를 동시에 표현하는 그래프입니다. symbols() 함수를 이용하며 이는 R base의 그래픽 함수로 내장되어있는 기본 함수입니다.
symbols(x, y, circles=크기, inches=원최대크기조절, fg=테두리색, bg=바탕색, lwd=테두리 두께,
xlab=x축라벨, ylab=y축라벨, main=그래프이름)
text(x,y,labels=원위의 올릴 글자,cex=글자크기,col=글자색)-> text 함수에서의 x,y는 글자가 올라갈 좌표를 나타내주는 것이기 때문에 symbols의 x,y과 같게 써줘야 제대로 올라갑니다.
bubble_d <- data.frame(
Category = factor(c("A","B","C")),
Value = c(100,200,300),
Size=c(40,50,60)
)
bubble_d
symbols(bubble_d$Category, bubble_d$Value,
circles=bubble_d$Size,
inches=0.3,
fg="white",
bg="lightgray",
lwd=1.5)
text(bubble_d$Category, bubble_d$Value,
bubble_d$Category,
cex=0.6,
col="brown")-> 첫 번째 이미지를 그릴 때 사용한 함수입니다. bubble_d$Category는 factor기 때문에 내부적으로 숫자값을 가지며, symbols에서는 숫자형태의 데이터를 기대하기 때문에 숫자로 변환되어 사용됩니다. 해당 그래프는 Category가 증가할수록(A에서 C로 갈수록), Value와 Size가 모두 증가하는 양의 경향을 보입니다.

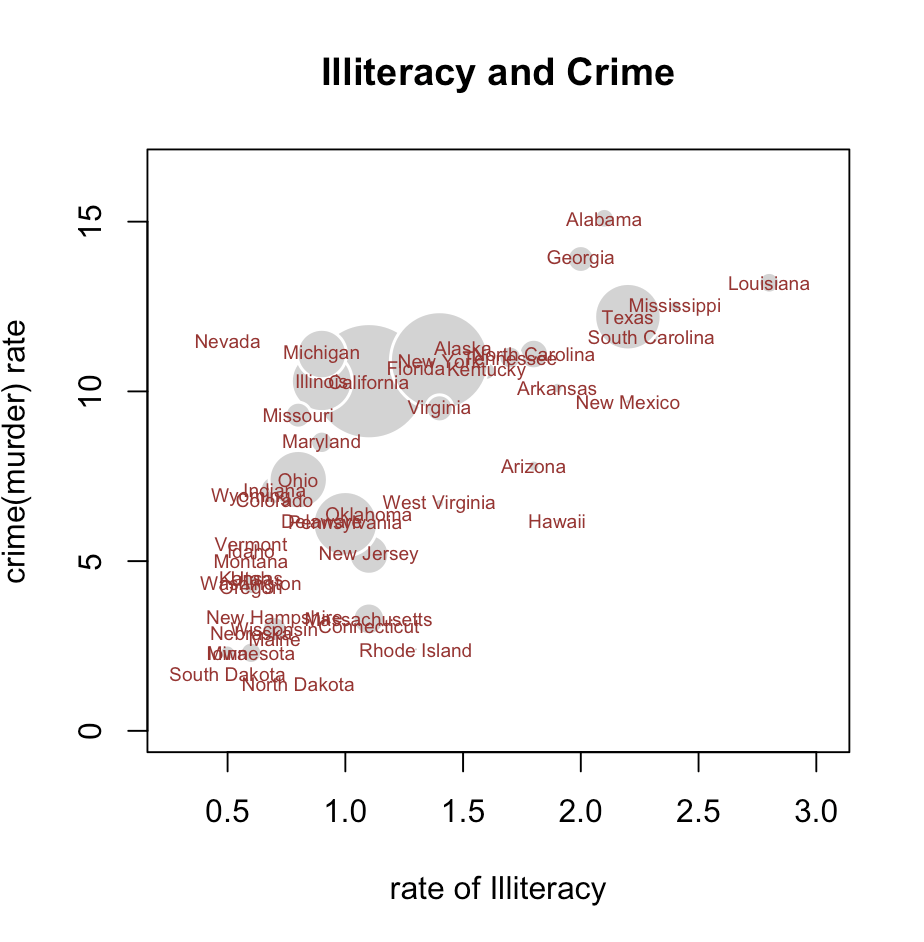
st <- data.frame(state.x77)
symbols(st$Illiteracy, st$Murder,
circles=st$Population,
inches=0.3,
fg="white",
bg="lightgray",
lwd=1.5,
xlab="rate of Illiteracy",
ylab="crime(murder) rate",
main="Illiteracy and Crime")
text(st$Illiteracy, st$Murder,
rownames(st),
cex=0.6,
col="brown")-> 두 번째 이미지를 그릴 때 사용한 함수입니다. 이 버블차트을 해석해보면 전반적으로 문맹률(x축, st$Illiteracy)가 높아질수록 범죄율(y축, st$Murder)가 증가하는 추세이며, 인구수가 많은 주(원의 크기가 큰 주, st$Population)가 대체로 범죄율도 높은 것으로 확인됩니다. 범죄율이 가장 낮은 주는 y축이 제일 작은 주인 North Dakota입니다.
(3) ggplot2는 R base 그래픽 함수보다 더 미적인 시각화를 하기 위해 사용하는 라이브러리로, 그래프를 그릴 때 구성요소를 쌓아서 만드는 특징이 있습니다. 하나의 ggplot() 함수와 여러개의 geom_xx() 함수들이 +로 연결되어 하나의 그래프를 완성합니다.
ggplot(데이터, aes(x=x값,y=y값))+
geom_xx(...)
1️⃣ 막대그래프(geom_bar(...))
month <- c(1,2,3,4,5,6)
rain <- c(55,50,45,50,60,70)
df <- data.frame(month,rain)
df
# month rain
# 1 1 55
# 2 2 50
# 3 3 45
# 4 4 50
# 5 5 60
# 6 6 70
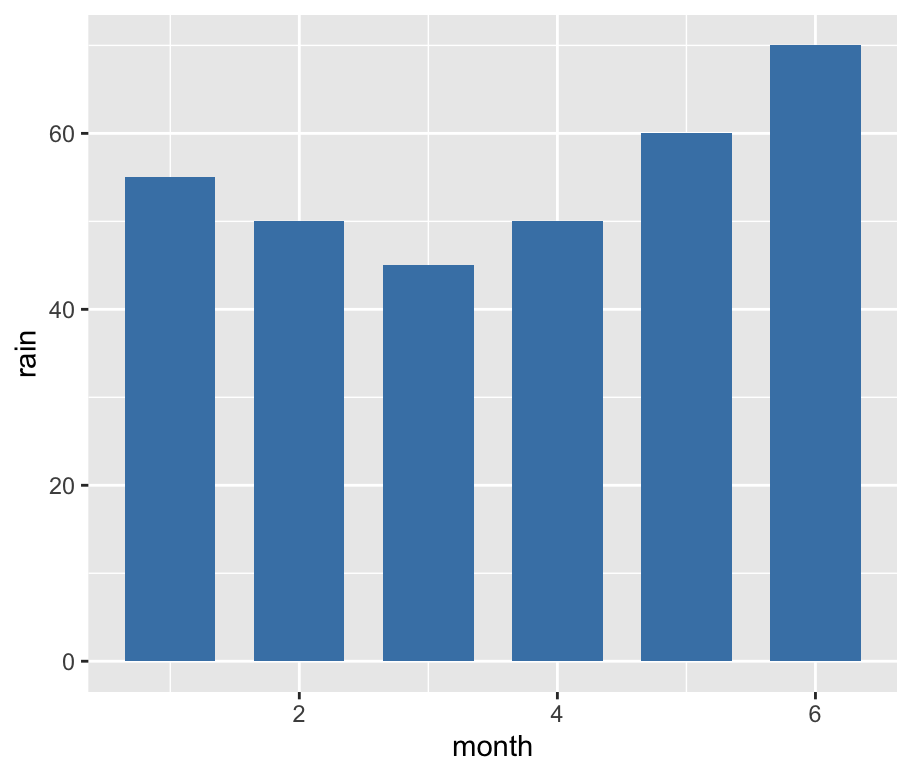
ggplot(df,aes(x=month, y=rain))+
geom_bar(stat="identity",
width=0.7,
fill="steelblue")-> 막대 그래프를 그릴 때는 geom_bar() 함수가 사용되며, 막대그래프(범주형, 단일변수)일 때 사용되는 함수이기 때문에 내부에 자동으로 범주의 개수를 세려고 합니다. 만약 위처럼 y축을 지정해줘야한다면, stat="identity" 속성을 주어 지정한 y축에 해당하는 열에 의해서 높이가 결정되도록 지정해줍니다. width는 막대의 넓이, fill은 색깔을 지정합니다.(만약 테두리색을 지정하고 싶으면 col을 통해 지정합니다.)
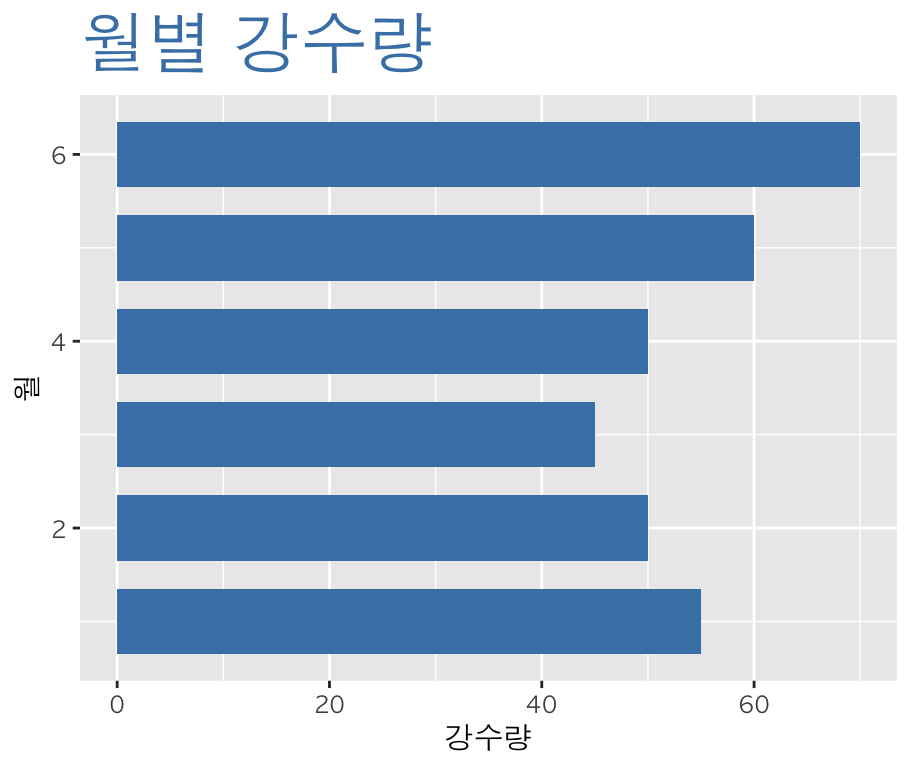
ggplot(df,aes(x=month, y=rain)) +
geom_bar(stat="identity",
width=0.7,
fill="steelblue") +
ggtitle("월별 강수량") +
theme(plot.title = element_text(size=25,face="bold",colour="steelblue"),
text = element_text(family="AppleGothic")) +
labs(x="월", y="강수량") + #레이블값 지정
coord_flip() #막대를 가로로 표시하게함-> 두 번째 이미지를 그린 함수로, ggtitle() 함수를 통해 제목을 지정해주며, theme() 함수를 통해 지정한 제목의 글자의 특성(크기, 스타일, 색깔)을 지정해주며 labs() 함수를 통해 레이블 값을 지정해줍니다. coord_filp()을 통해 막대를 가로로 표시하게 합니다.
2️⃣ 히스토그램(geom_histogram(...))
ggplot(iris,aes(x=Petal.Length)) +
geom_histogram(binwidth=0.5)-> 히스토그램을 그릴 때는 geom_histogram() 함수를 사용하며 binwidth를 통해 구간의 크기를 지정해줍니다.
-> 해당 히스토그램은 붓꽃의 품종을 따지지 않고 150송이 전체를 두고 봤을 때 Petal(꽃잎) 길이가 1~2cm인 애들이 꽤 있고, 4~6cm인 애들이 많다는 전체적인 분포를 보여줍니다.


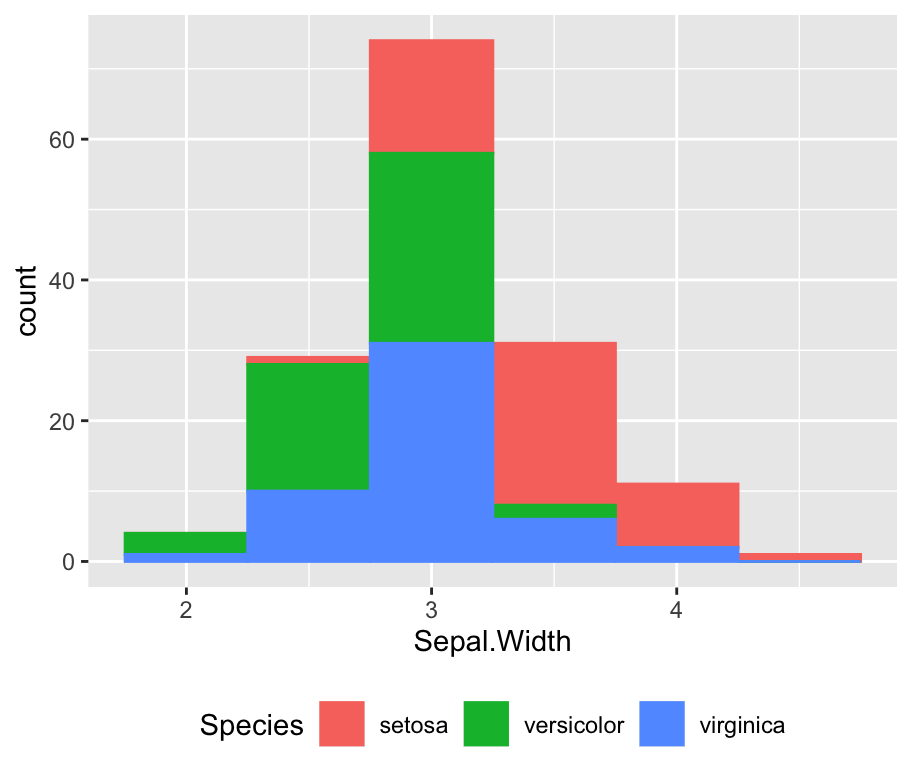
ggplot(iris,aes(x=Sepal.Width, fill=Species, color=Species)) +
geom_histogram(binwidth=0.5, position="dodge") +
theme(legend.position="top")-> 막대의 안쪽 색과 테두리 색을 품종별로 다르게 색칠하라고 aes 내부에서 fill, color를 통해 지정해줍니다. 그래서 그래프를 봤을 때 setosa, versicolor, virginica에 따라 색이 다르게 지정되어있는 것입니다.
-> position="dodge"라는 옵션을 통해 세가지 막대가 세 번째 이미지처럼 탑으로 쌓이지 않고 양옆으로 나란히 비켜서 있게 된 것이빈다. 그리고 legend.position="top"인게 두 번째 이미지의 경우, 만약 "bottom"값으로 변경하면 세 번째 이미지처럼 아래에 들어가게됩니다.
-> 이 그래프를 통해 Sepal(꽃받침)의 너비가 setosa 품종이 다른 두 품종에 비해 넓다는 사실을 알 수 있습니다.
3️⃣ 산점도(geom_point(...))
ggplot(iris,aes(x=Petal.Length, y=Petal.Width)) +
geom_point()-> 산점도를 그릴 때는 geom_point() 함수를 사용합니다. 첫 번째 이미지의 그래프를 그린 함수로, 꽃잎의 길이와 너비는 양의 상관관계를 가짐을 알 수 있습니다.

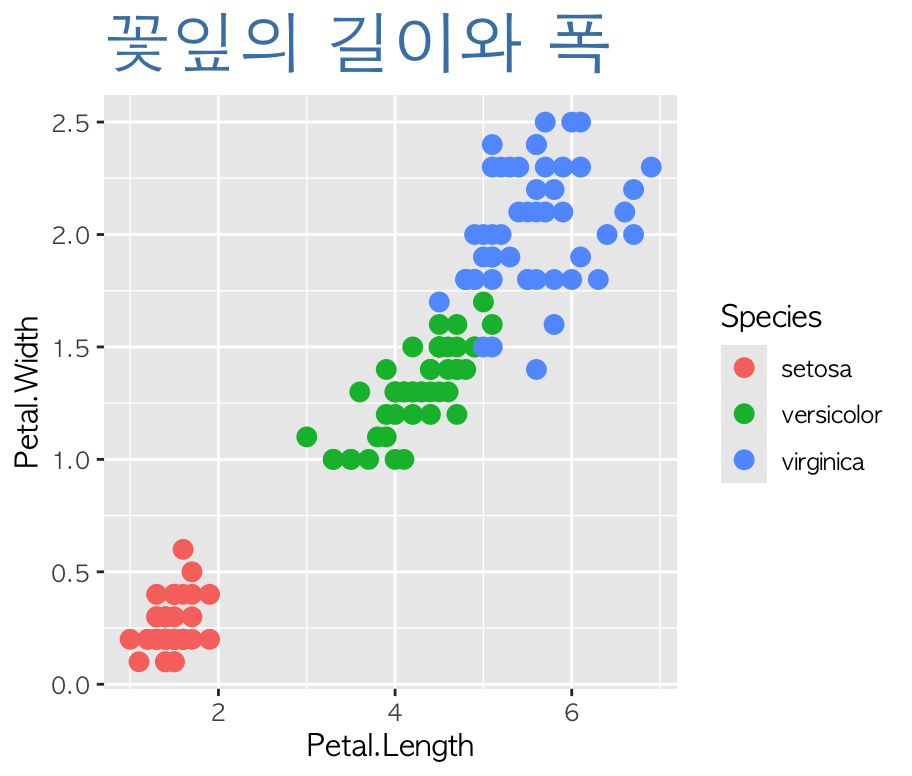
ggplot(iris,aes(x=Petal.Length, y=Petal.Width, color=Species)) +
geom_point(size=3) +
ggtitle("꽃잎의 길이와 폭") +
theme(plot.title = element_text(size=25,face="bold",colour="steelblue"),
text = element_text(family="AppleGothic"))-> 두 번째 이미지의 그래프르를 그린 함수로, size=3으로 키워 옆의 그래프보다 더 큰 point 크기를 가지며, color를 지정해주므로서 품종별로 다른 색을 가집니다.
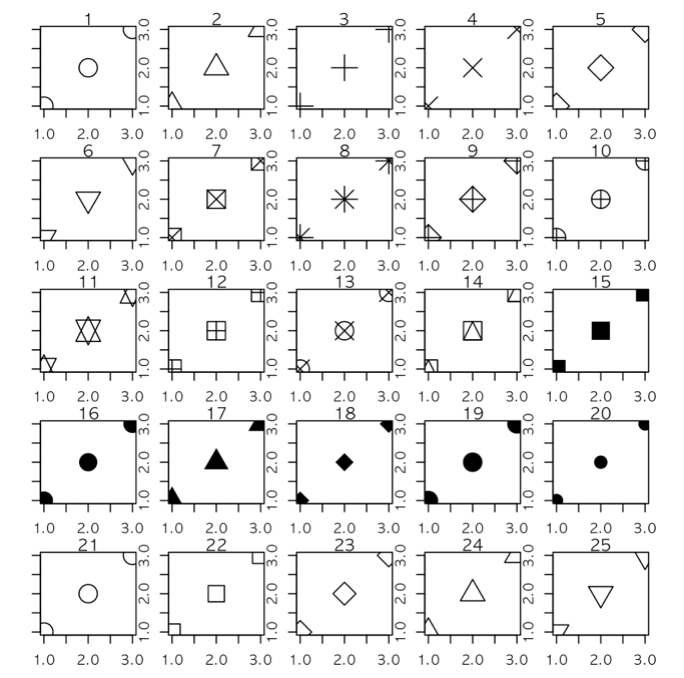
Q. 왜 점의 색을 지정할 때 fill이 아닌 color를 통해 지정하나요?
A. 이전 글에서 설명했던 것처럼 산점도에서는 0(점없음)~25까지의 총 26종의 모양을 가집니다. 그런데 이 이미지를 통해 보면 1번, 16번, 19번,20번,21번의 차이를 알기 어렵습니다. 1번은 빈 동그라미이며, 16번은 꽉찬 동그라미입니다. 19번은 기본 점으로, R 내부적으로 테두리를 미세하게 차이를 두어 화면에 더 부드럽게 렌더링됩니다. 20번은 좀 더 작은 꽉찬 동그라미이며, 21번은 테두리 선과 안쪽면이 분리된 고급형 입니다. 그래서 1,16,19,20번의 경우 모두 색상 적용 옵션이 color지만, 21번만이 fill(안쪽면)과 color(테두리)의 차이를 가집니다. 21번 ~ 25번까지의 모양이 모두 그런 특징을 가지고 있습니다.
[R] 단일&다중변수자료의 탐색
1. 자료- 자료의 특성과 변수의 개수에 따른 분류를 통해 범주/연속형 자료로, 단일/다중변수 자료로 나눌 수 있습니다.-> 자료의 특성에 따른 분류• 범주형 자료: 숫자의 크고 작음이 아니라, 종
in-ouput91.tistory.com
ggplot(iris,aes(x=Petal.Length, y=Petal.Width, fill=Species)) + #fill로 변경하니까 품종별로 색나누지못함
geom_point(size=3) +
ggtitle("꽃잎의 길이와 폭") +
theme(plot.title = element_text(size=25,face="bold",colour="steelblue"),
text = element_text(family="AppleGothic"))
ggplot(iris, aes(x=Petal.Length, y=Petal.Width, fill=Species)) + # color 대신 fill 사용!
# shape=21을 통해 테두리가 있는 동그라미로 설정
# color="black"으로 모든 점의 테두리를 검정색으로 지정
# stroke=1로 테두리 두께를 살짝 줍니다.
geom_point(shape=21, color="black", size=4, stroke=1) +
ggtitle("꽃잎의 길이와 폭") +
theme(plot.title = element_text(size=25, face="bold", colour="steelblue"),
text = element_text(family="AppleGothic"))

library(ggplot2)
head(mtcars[,c(1,2,4,6)])
# mpg cyl hp wt
# Mazda RX4 21.0 6 110 2.620
# Mazda RX4 Wag 21.0 6 110 2.875
# Datsun 710 22.8 4 93 2.320
# Hornet 4 Drive 21.4 6 110 3.215
# Hornet Sportabout 18.7 8 175 3.440
# Valiant 18.1 6 105 3.460
ggplot(data=mtcars, aes(x=wt,y=mpg,color=hp, shape=factor(cyl))) +
geom_point(size=3)+
ggtitle("차량 무게와 연비의 관계") +
theme(text = element_text(family="AppleGothic"))-> 산점도의 점 모양을 다르게 하고싶을 때는 그룹을 나타내는 팩터나 문자열이 들어가야합니다. 그래서 factor로 감싸줍니다. 위에서 color나 fill에도 뚜렷한 색깔을 나누는 경우에는 팩터를 넣어줘야합니다. ( iris의 Species 열은 원래 factor 입니다.)

4️⃣ 상자 수염 그래프(geom_boxplot(...))
ggplot(data=iris, aes(y=Petal.Length)) +
geom_boxplot(fill="yellow")-> 상자 수염 그래프를 그릴 때는 geom_boxplot() 함수를 사용하며 내부 색을 지정할 때는 fill을 사용합니다. 전체 붓꽃의 꽃잎 길이가 1cm~7cm 사이에 퍼져있다는 전체적인 덩어리를 볼 때 사용합니다.



ggplot(data=iris, aes(y=Petal.Length,fill=Species)) + # x=Species
geom_boxplot()-> fill=Species로 내부에서 지정하여 품종에 따라 색을 다르게 칠하며 상자도 품종별로 나눠야한다는 의미입니다. 세 번째 이미지처럼 x축에 이름을 넣고 싶으면 x축을 지정해주면 됩니다.
head(mtcars)
# mpg cyl disp hp drat wt qsec vs am gear carb
# Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
# Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
# Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
# Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
# Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
# Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
ggplot(data=mtcars, aes(y=mpg,fill=factor(gear))) +
geom_boxplot()-> $ gear: num 4 4 4 3 3 3 3 4 4 4 ... gear는 숫자형식으로, 명확한 값을 나누기 위해서는 factor로 감싸줘야합니다.

=> histogram에서는 x축만을 지정하여 y축을 자동으로 구간별로 개수(count) 세서 y축을 만들어주지만, boxplot에서는 자동 집계가 아니라 이미 존재하는 값의 분포를 보여주기 때문에 숫자 데이터인 y를 직접 지정해주기만 하면 됩니다. boxplot에서는 x축은 그룹 범주를 나누는 역할로 사용됩니다.
5️⃣ 선그래프(geom_line(...))
year <- 1937:1960
cnt <- as.vector(airmiles)
df <- data.frame(year,cnt)
head(df)
# year cnt
# 1 1937 412
# 2 1938 480
# 3 1939 683
# 4 1940 1052
# 5 1941 1385
# 6 1942 1418
ggplot(data=df,aes(x=year,y=cnt))+
geom_line(col="red")-> 선 그래프를 사용할 때는 geom_line() 함수를 사용합니다. 해당 그래프는 시간이 지남에 따라 항공 수요가 폭발적으로 증가함을 보여줍니다.

airmiles
# Time Series:
# Start = 1937
# End = 1960
# Frequency = 1
# [1] 412 480 683 1052 1385 1418 1634 2178
# [9] 3362 5948 6109 5981 6753 8003 10566 12528
# [17] 14760 16769 19819 22362 25340 25343 29269 30514
class(airmiles) #[1] "ts"-> airmiles은 1937년부터 1960년까지 미국 민영 항공사의 여객 마일리지 변화를 보여주는 내장 데이터로, ts 객체로 묶여있기 때문에 내부에서 사용할 때 as.vector()을 통해 순수한 숫자 데이터만을 뽑아냈어야합니다.
year <- c(2018:2023)
dust <- c(40,35,28,30,26,23)
df <- data.frame(year, dust)
ggplot(data=df, aes(x=year, y=dust))+
geom_line(col="steelblue",size=1.5)+
ggtitle("연도별 미세머지 평균 농도") +
theme(text = element_text(family="AppleGothic"))-> 선의 두께를 두껍게 하고 싶으면 size를 크게 지정해주면 됩니다.

'Programming Language > R' 카테고리의 다른 글
| [R] 머신러닝(2): 텍스트마이닝- 감성분석 (0) | 2026.05.28 |
|---|---|
| [R] 머신러닝(1): 연관규칙분석-아프리오리 알고리즘 (0) | 2026.05.23 |
| [R] 데이터 전처리 (0) | 2026.04.26 |
| [R] 단일&다중변수자료의 탐색 (0) | 2026.04.25 |
| [R] 기초문법(조건문, 반복문, 함수) (0) | 2026.04.06 |



