

091
[R] 머신러닝(3): 군집분석 - K-means 군집분석 본문
1. 군집분석 이론

- 군집분석이란 정답(Label)이 없는 데이터에서 비슷한 것들끼리 자동으로 묶는 비지도 학습 중 일종입니다. 군집분석에는 계층적 군집과 분할적 군집으로 나뉩니다.
• 계층적 군집은 각 관측지를 하나의 최초 군집으로 지정한 후, 한번에 두개씩 하나의 군집으로 생성합니다. 모든 군집들이 하나의 군집이 될 때까지 군집들을 결합해 나가는 방법입니다.
• 분할적 군집은 처음에 군집수인 k를 지정한 후, 관측치들을 무작위로 k개의 집단으로 분할해줍니다. 다양한 기준(평균값, 최빈값 등)을 이용하여 centroid를 수정해 나가며 집단을 다시 재분류하는 방법입니다.
| 계층적 군집 | 분할적 군집 | |
| 방법 | 모든 데이터를 하나씩 합쳐가며 계층 형성 | 처음에 k개 그룹으로 쪼개고 계속 재조정 |
| k 지정 | 불필요 | 필요 |
| 결과 | 트리 구조(덴드로그램) | k개의 군집 |
| 대표 알고리즘 | Hierarchical | K-means |
- K-means 군집은 주어진 데이터를 k개의 군집으로 묶는 알고리즘으로 가장 대표적인 군집 방법입니다.


-> step 3에서 나머지 모든 점에서 각 중심점까지 유클리디안 거리를 계산하여 더 가까운 중심점의 군집으로 배정합니다.
- 유클리디안 거리(Euclidean Distance)는 K-means에서 가까운 중심점을 판단할 때 쓰는 거리 계산법입니다.
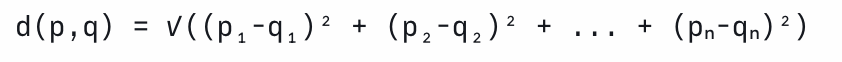

-> 시력의 경우 0.3 차이는 거리에 영향을 거의 주지 못하고 키가 유사도 거리를 지배해버리기 때문에 두 변수값의 영향력을 동일하게 하고 싶다면 정규화가 필요합니다.
- 데이터 정규화란 모든 변수가 거리 계산에 동등한 영향을 갖도록 하기 위해서 모든 변수의 자료 범위를 0~1 사이로 정규화 한 후에 거리 계산을 하는 과정을 의미합니다.

- 군집분석은 비지도 학습으로 정답이 없기 떄문에 분류의 accuracy같은 개념을 직접 사용할 수 없습니다. 그렇기 때문에 군집이 데이터를 얼마나 잘 설명하는지 분산 기반 지표로 간접 평가합니다.

| 지표 | 의미 |
| betweenss | 군집 간 분산(중심점들이 서로 얼마나 멀리 있나) |
| totss | 전체 분산(군집 구분 없이 전체 데이터의 퍼짐 정도) |
| 비율 | 전체 분산 중 군집 간 분산이 차지하는 비율 |
-> 비율이 0.7 이상일 때는 괜찮은 군집, 0.9 이상일 때는 매우 좋은 군집으로 즉 1에 가까울 수록 군집이 잘 분리됨을 나타냅니다.
2. 군집분석 실습
std <- function(X) {
return((X - min(X)) / (max(X) - min(X)))
}
mydata <- apply(iris[c(1:6), c(1,2)], 2, std)(0) 정규화 함수를 만들어서 열 단위로 적용해줍니다.
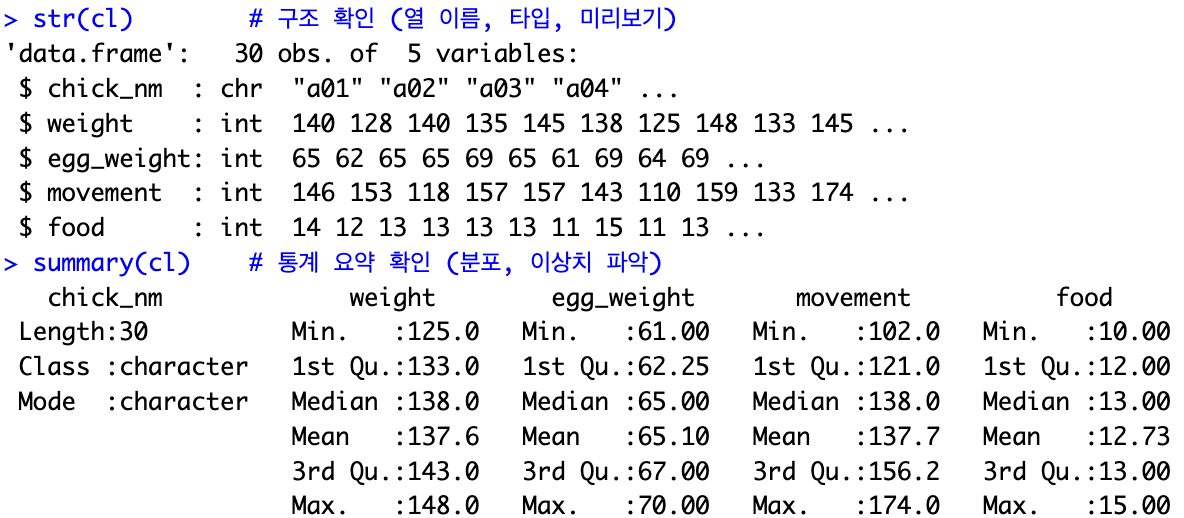
cl <- read.csv("chick.csv", header=T)
str(cl) # 구조 확인 (열 이름, 타입, 미리보기)
summary(cl) # 통계 요약 확인 (분포, 이상치 파악)(0.1) 데이터를 가져올 때 데이터의 구조와 통계 요약을 각각 str 함수와 summary 함수를 통해 알 수 있습니다.
library(cluster)
mydata <- iris[, 1:4]
fit <- kmeans(x=mydata, centers=3)
#kmeans(x=숫자형 데이터프레임 또는 행렬, centers=군집 수 k)
fit(1) 패키지를 가져와준 뒤 kmeans를 기본 실행해줍니다.

fit$cluster # 각 관측치의 군집 번호
fit$centers # 각 군집의 중심점 좌표(2) 위의 fit을 출력했을 때 보였던 Available components를 통해 군집 결과를 상세 확인할 수 있습니다.
| 속성 | 내용 |
| fit$cluster | 각 행이 몇 번 군집인지 벡터 |
| fit$centers | 각 군집의 중심점(k x 변수 행렬) |
| fit$totss | 전체 분산 |
| fit$withinss | 각 군집 내 분산 벡터 |
| fit$tot.withinss | 군집 내 분산 합계 |
| fit$betweenss | 군집 간 분산 |
| fit$size | 각 군집의 데이터 개수 |
subset(mydataOr, fitOr$cluster == 1)
subset(mydataOr, fitOr$cluster == 2)(2.1) 특정 군집 데이터를 추출할 때는 subset 함수를 사용합니다.
clusplot(mydata, fit$cluster, color=T, shade=T, labels=1, lines=0)
clusplot(mydata, fit$cluster, color=T, shade=F, labels=1, lines=0)
clusplot(mydata, fit$cluster, color=T, shade=F, labels=2, lines=0)
clusplot(mydata, fit$cluster, color=T, shade=F, labels=1, lines=1)
#clusplot(x=데이터프레임, clus=군집 번호 벡터, color=군집별 색상 구분,
# shade=군집 영역 빗금, labels=1(군진번호X),2(군집번호표시),lines=0(선X),1(중-중),2(경-경))(3) 군집 시각화를 할 수 있습니다.




-> labels가 2일 때는 군집 번호를 표시하고 1일때는 군지번호를 표시하지 않습니다.
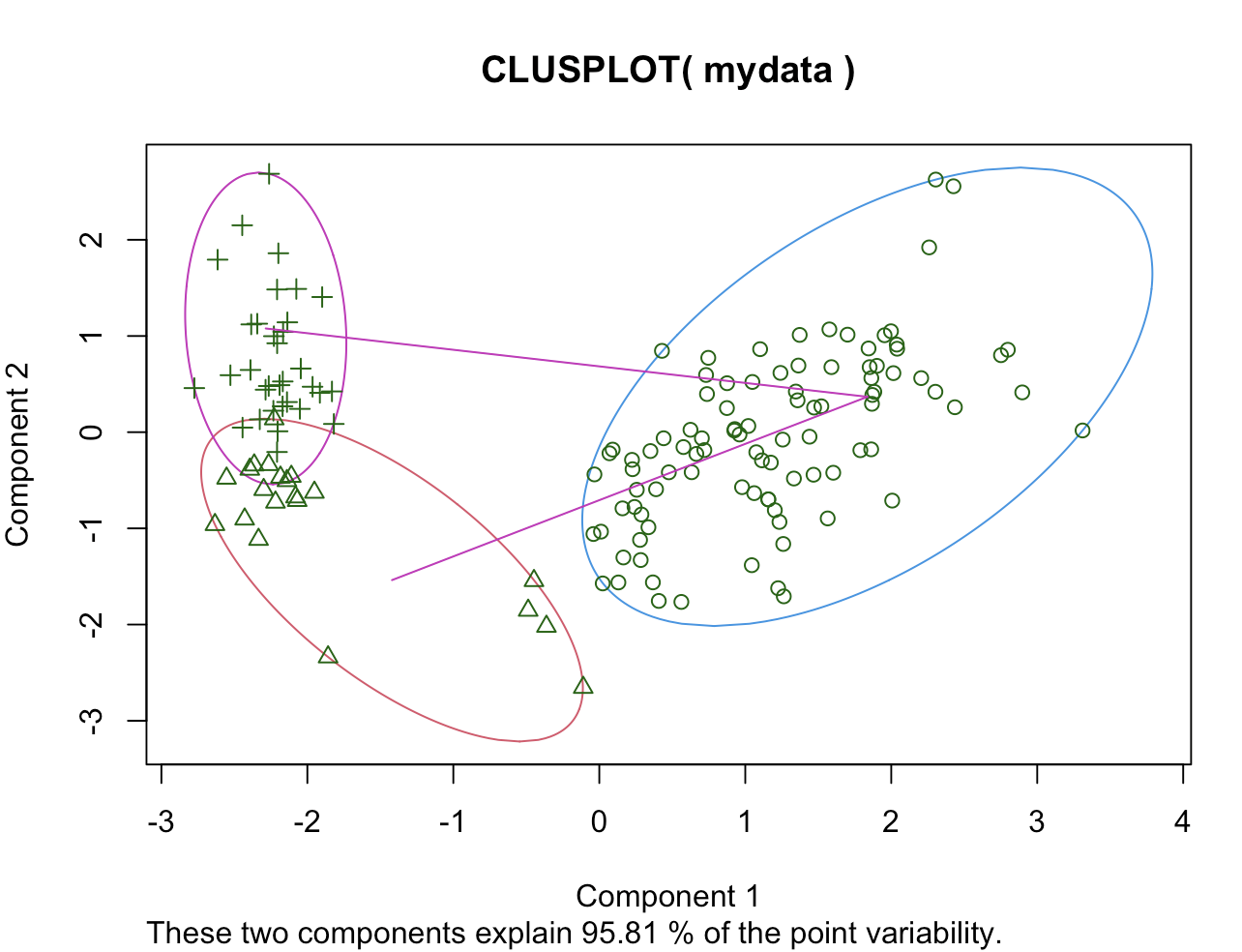

-> lines가 0일 때는 위의 이미지들 처럼 선이 그려지지 않지만, 1일 때는 각 데이터 포인트까지 선이 그려지고, 2일 때는 군집의 중심에서 군집의 경계까지 선이 그려집니다.
fit$betweenss/fit$totss #[1] 0.8842753(4) 군집 품질을 평가해줍니다. 위의 fit 변수 출력 이미지에서 나왔던 88.4%와 같은 값을 확인할 수 있습니다.
cl_kmc <- kmeans(cl[,2:3], centers=3)
cl$cluster <- cl_kmc$cluster # 원본 데이터에 군집 번호 열 추가
head(cl)
plot(cl$food, cl$weight,col=c("red","blue","green")[cl$cluster])(5) 군집 번호를 원본 데이터에 추가해준 뒤 색상으로 시각화해줍니다.


'Programming Language > R' 카테고리의 다른 글
| [R] 머신러닝(4): 회귀분석 - 다중선형 회귀분석, 로지스틱 회귀분석 (0) | 2026.05.30 |
|---|---|
| [R] 머신러닝(2): 텍스트마이닝- 감성분석 (0) | 2026.05.28 |
| [R] 머신러닝(1): 연관규칙분석-아프리오리 알고리즘 (0) | 2026.05.23 |
| [R] 데이터 시각화(treemap, ggplot2) (0) | 2026.04.26 |
| [R] 데이터 전처리 (0) | 2026.04.26 |



